1124
[14주차 - Day5] NLP: 과제
과제: Word2Vec, Skip-gram 모델을 사용한 subword 임베딩
# 예제 코드 및 실습https://www.tensorflow.org/tutorials/text/word2vec
word2vec | TensorFlow Core
WiML 심포지엄 2023에서 기계 학습, 생성 AI 등에 대한 최신 정보를 알아보세요. word2vec 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. word2vec은 단일 알고리즘
www.tensorflow.org
위의 예제 코드를 기반으로 진행된 실습임을 알립니다
word2vec
: 단일 알고리즘이 아니며 그보다는 대규모 데이터세트에서 단어 임베딩을 학습하는 데 사용할 수 있는 모델 아키텍처 및 최적화 제품군이다.
벡터 공간의 단어 표현 효율적인 평가 및 단어 및 구문의 분산된 표현 및 구성성, 이러한 논문들은 단어 표현을 학습하는 데 두 가지 메서드를 제안한다.
- 지속적인 bag-of-words 모델: 주변의 콘텍스트 단어를 바탕으로 중간 단어를 예측합니다. 콘텍스트는 현재(중간) 단어의 앞과 뒤의 몇몇 단어로 구성되어 있습니다. 이 아키텍처는 콘텍스트의 단어 순서가 중요하지 않기 때문에 bag-of-words 모델이라고 불립니다.
- 지속적인 skip-gram 모델: 동일한 문장 내의 현재 단어의 앞과 뒤 일정 범위 내의 단어를 예측합니다. 이에 대한 작업 예제는 아래와 같습니다.
이 튜토리얼에서는 skip-gram 접근 방식을 사용한다.
Skip-gram 및 네거티브 샘플링
bag-of-words 모델이 주변의 콘텍스트가 주어지면 단어를 예측하는 한편, skip-gram 모델은 단어 자체가 주어지면 단어의 콘텍스트(또는 주변)을 예측한다. 모델은 토큰을 생략할 수 있는 n-grams인 skip-grams에서 훈련된다.
N-gram 언어 모델은 이처럼 다음 단어를 예측할 때 문장 내 모든 단어를 고려하지 않고 특정 단어의 개수(N)만 고려합니다. 즉, N-gram은 N개의 연속적인 단어의 나열을 하나의 묶음(=token)으로 간주한다.
예제 문장 벡터화
The wide road shimmered in the hot sun.
다음의 문장을 토큰화한다.
sentence = "The wide road shimmered in the hot sun"
tokens = list(sentence.lower().split())
print(len(tokens))어휘를 생성하여 토큰에서 정수 인덱스로 매핑을 저장한다.
vocab, index = {}, 1 # start indexing from 1
vocab['<pad>'] = 0 # add a padding token
for token in tokens:
if token not in vocab:
vocab[token] = index
index += 1
vocab_size = len(vocab)
print(vocab)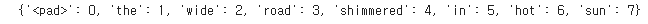
정반대의 어휘를 생성하여 정수 인덱스에서 토큰으로 매핑을 저장한다.
inverse_vocab = {index: token for token, index in vocab.items()}
print(inverse_vocab)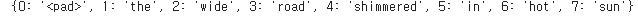
문장을 벡터화한다.
example_sequence = [vocab[word] for word in tokens]
print(example_sequence)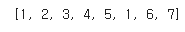
한 문장에서 skip-grams 생성하기
<tf.keras.preprocessing.sequence> 모듈은 word2vec에 대한 데이터 준비를 단순화하는 유용한 함수를 제공한다. <tf.keras.preprocessing.sequence.skipgrams>를 사용해 범위 [0, vocab_size)의 토큰에서 주어진 window_size를 통해 <example_sequence>에서 skip-gram 쌍을 생성할 수 있다.
window_size = 2
positive_skip_grams, _ = tf.keras.preprocessing.sequence.skipgrams(
example_sequence,
vocabulary_size=vocab_size,
window_size=window_size,
negative_samples=0)
print(len(positive_skip_grams))몇몇 네거티브 skip-grams을 프린트
for target, context in positive_skip_grams[:5]:
print(f"({target}, {context}): ({inverse_vocab[target]}, {inverse_vocab[context]})")
하나의 skip-gram에 대한 네거티브 샘플링
<skipgrams> 함수는 주어진 윈도 범위를 슬라이딩하여 모든 포지티브 skip-gram 쌍을 반환한다. 훈련을 위한 네거티브 샘플 역할을 할 추가 skip-gram 쌍을 생성하려면 어휘에서 랜덤 단어를 샘플링해야 한다. <tf.random.log_uniform_candidate_sampler> 함수를 사용해 윈도의 주어진 대상 단어에 대한 네거티브 샘플 <num_ns>개를 샘플링한다. 하나의 skip-gram의 대상 단어에서 함수를 호출하고 true 클래스로 콘텍스트 단어를 전달해 샘플링에서 제외할 수 있다.
# Get target and context words for one positive skip-gram.
target_word, context_word = positive_skip_grams[0]
# Set the number of negative samples per positive context.
num_ns = 4
context_class = tf.reshape(tf.constant(context_word, dtype="int64"), (1, 1))
negative_sampling_candidates, _, _ = tf.random.log_uniform_candidate_sampler(
true_classes=context_class, # class that should be sampled as 'positive'
num_true=1, # each positive skip-gram has 1 positive context class
num_sampled=num_ns, # number of negative context words to sample
unique=True, # all the negative samples should be unique
range_max=vocab_size, # pick index of the samples from [0, vocab_size]
seed=SEED, # seed for reproducibility
name="negative_sampling" # name of this operation
)
print(negative_sampling_candidates)
print([inverse_vocab[index.numpy()] for index in negative_sampling_candidates])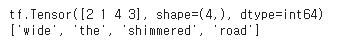
하나의 훈련 예제 구성하기
주어진 포지티브 <(target_word, context_word)> skip-gram의 경우, 이제 또한 <target_word>의 윈도 사이즈 주변에 표시되지 않는 <num_ns> 네거티브 샘플링된 콘텍스트 단어도 있다. 1 포지티브 <context_word> 및 <num_ns> 네거티브 콘텍스트 단어를 하나의 텐서로 배치한다. 이는 각 대상 단어에 대한 일련의 포지티브 skip-grams(1로 레이블링 됨) 및 네거티브 샘플(0으로 레이블링 됨)을 생성한다.
# Reduce a dimension so you can use concatenation (in the next step).
squeezed_context_class = tf.squeeze(context_class, 1)
# Concatenate a positive context word with negative sampled words.
context = tf.concat([squeezed_context_class, negative_sampling_candidates], 0)
# Label the first context word as `1` (positive) followed by `num_ns` `0`s (negative).
label = tf.constant([1] + [0]*num_ns, dtype="int64")
target = target_word위의 skip-gram 예제의 대상 단어에 대한 콘텍스트와 해당 레이블을 확인한다.
print(f"target_index : {target}")
print(f"target_word : {inverse_vocab[target_word]}")
print(f"context_indices : {context}")
print(f"context_words : {[inverse_vocab[c.numpy()] for c in context]}")
print(f"label : {label}")
<(target, context, label)> 텐서의 튜플은 skip-gram 네거티브 샘플링 word2vec 모델 훈련을 위한 하나의 훈련 예제로 구성되어 있다. 콘텍스트 및 레이블의 형태는 <(1+num_ns,)>인 반면 대상의 형태는 <(1,)>인 점에 주의.
print("target :", target)
print("context :", context)
print("label :", label)
모든 단계를 하나의 함수로 컴파일
Skip-gram 샘플링 표
<tf.keras.preprocessing.sequence.skipgrams> 함수는 샘플링 표 인수를 허용하여 모든 토큰을 샘플링 하는 확률을 인코딩한다. <tf.keras.preprocessing.sequence.make_sampling_table>을 사용해 확률적 샘플링 표를 기반으로 한 단어 빈도 순위를 생성하고 이를 skipgrams 함수에 전달할 수 있다. 10의 vocab_size에 대한 샘플링 확률을 검사한다.
sampling_table = tf.keras.preprocessing.sequence.make_sampling_table(size=10)
print(sampling_table)
<sampling_table[i]>은 데이터세트의 i번째로 가장 흔한 단어를 샘플링 할 확률을 의미.
훈련 데이터 생성하기
# Generates skip-gram pairs with negative sampling for a list of sequences
# (int-encoded sentences) based on window size, number of negative samples
# and vocabulary size.
def generate_training_data(sequences, window_size, num_ns, vocab_size, seed):
# Elements of each training example are appended to these lists.
targets, contexts, labels = [], [], []
# Build the sampling table for `vocab_size` tokens.
sampling_table = tf.keras.preprocessing.sequence.make_sampling_table(vocab_size)
# Iterate over all sequences (sentences) in the dataset.
for sequence in tqdm.tqdm(sequences):
# Generate positive skip-gram pairs for a sequence (sentence).
positive_skip_grams, _ = tf.keras.preprocessing.sequence.skipgrams(
sequence,
vocabulary_size=vocab_size,
sampling_table=sampling_table,
window_size=window_size,
negative_samples=0)
# Iterate over each positive skip-gram pair to produce training examples
# with a positive context word and negative samples.
for target_word, context_word in positive_skip_grams:
context_class = tf.expand_dims(
tf.constant([context_word], dtype="int64"), 1)
negative_sampling_candidates, _, _ = tf.random.log_uniform_candidate_sampler(
true_classes=context_class,
num_true=1,
num_sampled=num_ns,
unique=True,
range_max=vocab_size,
seed=seed,
name="negative_sampling")
# Build context and label vectors (for one target word)
context = tf.concat([tf.squeeze(context_class,1), negative_sampling_candidates], 0)
label = tf.constant([1] + [0]*num_ns, dtype="int64")
# Append each element from the training example to global lists.
targets.append(target_word)
contexts.append(context)
labels.append(label)
return targets, contexts, labels
word2vec에 대한 훈련 데이터 준비하기
텍스트 말뭉치 다운로드
이 튜토리얼에서는 Shakespeare가 작성한 텍스트 파일을 사용
path_to_file = tf.keras.utils.get_file('shakespeare.txt', 'https://storage.googleapis.com/download.tensorflow.org/data/shakespeare.txt')파일에서 텍스트를 읽고 처음 몇 개의 라인을 프린트.
with open(path_to_file) as f:
lines = f.read().splitlines()
for line in lines[:20]:
print(line)
공백이 없는 라인을 사용해 다음 단계를 위해 <tf.data.TextLineDataset> 객체를 구성한다.
text_ds = tf.data.TextLineDataset(path_to_file).filter(lambda x: tf.cast(tf.strings.length(x), bool))
말뭉치에서 문장 벡터화
<TextVectorization> 레이어를 사용하여 말뭉치의 문장을 벡터화할 수 있다.
# Now, create a custom standardization function to lowercase the text and
# remove punctuation.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
return tf.strings.regex_replace(lowercase,
'[%s]' % re.escape(string.punctuation), '')
# Define the vocabulary size and the number of words in a sequence.
vocab_size = 4096
sequence_length = 10
# Use the `TextVectorization` layer to normalize, split, and map strings to
# integers. Set the `output_sequence_length` length to pad all samples to the
# same length.
vectorize_layer = layers.TextVectorization(
standardize=custom_standardization,
max_tokens=vocab_size,
output_mode='int',
output_sequence_length=sequence_length)텍스트 데이터세트에서 <TextVectorization.adapt>를 호출하여 어휘를 생성한다.
vectorize_layer.adapt(text_ds.batch(1024))레이어의 상태가 텍스트 말뭉치를 나타내기 위해 조정되면 어휘는 <TextVectorization.get_vocabulary>로 액세스할 수 있다. 이 함수는 빈도로 정렬된(내림차순) 모든 어휘 토큰의 목록을 반환한다.
# Save the created vocabulary for reference.
inverse_vocab = vectorize_layer.get_vocabulary()
print(inverse_vocab[:20])<vectorize_layer>는 이제 <text_ds( tf.data.Dataset)>의 각 요소에 대한 벡터를 생성하는 데 사용할 수 있다. <Dataset.batch, Dataset.prefetch, Dataset.map 및 Dataset.unbatch>를 적용한다.
# Vectorize the data in text_ds.
text_vector_ds = text_ds.batch(1024).prefetch(AUTOTUNE).map(vectorize_layer).unbatch()
데이터세트에서 시퀀스 획득하기
이제 정수 인코딩된 문장의 <tf.data.Dataset>가 있다. word2vec 모델을 훈련하기 위해 데이터세트를 준비하려면 데이터세트를 문장 벡터 시퀀스 목록으로 평면화한다. 이 단계는 데이터세트의 각 문장을 반복하여 포지티브 및 네거티브 예제를 생성하기 때문에 필요하다.
sequences = list(text_vector_ds.as_numpy_iterator())
print(len(sequences))
<sequences>에서 몇몇 예제를 검사한다.
for seq in sequences[:5]:
print(f"{seq} => {[inverse_vocab[i] for i in seq]}")
시퀀스에서 훈련 예제 생성하기
<sequences>는 이제 int로 인코딩된 문장의 목록이다. 이전에 정의된 <generate_training_data> 함수를 호출하여 word2vec 모델에 대한 훈련 예제를 생성한다. 요약하자면 함수는 각 시퀀스의 각 단어를 다시 반복하여 포지티브 및 네거티브 콘텍스트 단어를 수집한다. 대상, 콘텍스트 및 레이블의 길이는 동일해야 하며 훈련 예제의 총수를 나타낸다.
targets, contexts, labels = generate_training_data(
sequences=sequences,
window_size=2,
num_ns=4,
vocab_size=vocab_size,
seed=SEED)
targets = np.array(targets)
contexts = np.array(contexts)
labels = np.array(labels)
print('\n')
print(f"targets.shape: {targets.shape}")
print(f"contexts.shape: {contexts.shape}")
print(f"labels.shape: {labels.shape}")
성능을 높이기 위해 데이터세트 구성하기
잠재적으로 훈련 예제의 많은 수에 대한 효과적인 배치를 수행하려면 <tf.data.Dataset> API를 사용한다. 이 단계 후, word2vec 모델 훈련을 위한 <(target_word, context_word), (label)> 요소의 <tf.data.Dataset> 객체를 갖게 된다.
BATCH_SIZE = 1024
BUFFER_SIZE = 10000
dataset = tf.data.Dataset.from_tensor_slices(((targets, contexts), labels))
dataset = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE, drop_remainder=True)
print(dataset)<Dataset.cache 및 Dataset.prefetch>를 적용하여 성능을 개선한다.
dataset = dataset.cache().prefetch(buffer_size=AUTOTUNE)
print(dataset)
모델 및 훈련
word2vec 모델은 분류자로 구현되어 skip-grams의 True 콘텍스트 단어와 네거티브 샘플링을 통해 획득한 False 콘텍스트 단어를 식별할 수 있다. 대상 및 콘텍스트 단어의 임베딩 간 내적 곱셈을 수행하여 레이블에 대한 예측을 획득하고 데이터세트의 true 레이블에 대한 손실 함수를 계산할 수 있다.
하위 분류된 word2vec 모델
Keras 하위 클래스화 API를 사용해 다음 레이어를 통해 word2vec 모델을 정의합니다.
- target_embedding: 대상 단어로 나타났을 때 단어의 임베딩을 검색하는 tf.keras.layers.Embedding 레이어. 이 레이어의 매개변수 수는 (vocab_size * embedding_dim)입니다.
- context_embedding: 콘텍스트 단어로 나타났을 때 단어의 임베딩을 검색하는 다른 tf.keras.layers.Embedding 레이어. 이 레이어의 매개변수 수는 target_embedding의 매개변수의 수와 같습니다(즉, (vocab_size * embedding_dim)).
- dots: 대상의 내적과 훈련 쌍의 콘텍스트 임베딩을 계산하는 tf.keras.layers.Dot 레이어입니다.
- flatten: dots 레이어의 결과를 로짓으로 평면화하는 tf.keras.layers.Flatten 레이어입니다.
하위 분류된 모델로 해당 임베딩 레이어로 전달될 수 있는 (target, context) 쌍을 허용하는 call() 함수를 정의할 수 있습니다. context_embedding의 형상을 변경해 target_embedding로 내적을 수행하고 평면화된 결과를 반환합니다.
class Word2Vec(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim):
super(Word2Vec, self).__init__()
self.target_embedding = layers.Embedding(vocab_size,
embedding_dim,
input_length=1,
name="w2v_embedding")
self.context_embedding = layers.Embedding(vocab_size,
embedding_dim,
input_length=num_ns+1)
def call(self, pair):
target, context = pair
# target: (batch, dummy?) # The dummy axis doesn't exist in TF2.7+
# context: (batch, context)
if len(target.shape) == 2:
target = tf.squeeze(target, axis=1)
# target: (batch,)
word_emb = self.target_embedding(target)
# word_emb: (batch, embed)
context_emb = self.context_embedding(context)
# context_emb: (batch, context, embed)
dots = tf.einsum('be,bce->bc', word_emb, context_emb)
# dots: (batch, context)
return dots
손실 함수 정의 및 모델 컴파일
단순성을 위해, tf.keras.losses.CategoricalCrossEntropy를 네거티브 샘플링 손실에 대한 대안으로 사용할 수 있다. 자체 사용자 정의 손실 함수를 작성하고 싶다면 다음을 수행할 수도 있다.
def custom_loss(x_logit, y_true):
return tf.nn.sigmoid_cross_entropy_with_logits(logits=x_logit, labels=y_true)모델을 빌드해 보자. 128 임베딩 차원으로 word2vec 클래스를 인스턴스화한다(다른 값으로 실험할 수 있다), <tf.keras.optimizers.Adam> 옵티마이저로 모델을 컴파일한다.
embedding_dim = 128
word2vec = Word2Vec(vocab_size, embedding_dim)
word2vec.compile(optimizer='adam',
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])또한 콜백을 정의하여 TensorBoard에 대한 훈련 통계를 기록한다.
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir="logs")얼마간의 epoch 동안 dataset에서 모델을 훈련한다.
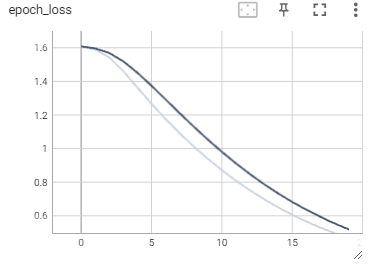
word2vec.fit(dataset, epochs=20, callbacks=[tensorboard_callback])
TensorBoard는 이제 word2vec 모델의 정확성과 손실을 표시.
#docs_infra: no_execute
%tensorboard --logdir logs
임베딩 검색 및 분석
Model.get_layer 및 Layer.get_weights을 사용해 모델에서 가중치를 얻는다. TextVectorization.get_vocabulary 함수는 어휘를 제공하여 라인당 하나의 토큰으로 메타데이터 파일을 빌드한다.
weights = word2vec.get_layer('w2v_embedding').get_weights()[0]
vocab = vectorize_layer.get_vocabulary()벡터 및 메타데이터 파일을 생성하고 저장한다.
out_v = io.open('vectors.tsv', 'w', encoding='utf-8')
out_m = io.open('metadata.tsv', 'w', encoding='utf-8')
for index, word in enumerate(vocab):
if index == 0:
continue # skip 0, it's padding.
vec = weights[index]
out_v.write('\t'.join([str(x) for x in vec]) + "\n")
out_m.write(word + "\n")
out_v.close()
out_m.close()vectors.tsv 및 metadata.tsv를 다운로드하여 Embedding Projector에서 획득한 임베딩을 분석한다.
try:
from google.colab import files
files.download('vectors.tsv')
files.download('metadata.tsv')
except Exception:
pass
'프로그래머스 데브 코스 > TIL' 카테고리의 다른 글
| [6기] 프로그래머스 인공지능 데브코스 87일차 TIL (0) | 2023.11.26 |
|---|---|
| [6기] 프로그래머스 인공지능 데브코스 86일차 TIL (0) | 2023.11.25 |
| [6기] 프로그래머스 인공지능 데브코스 84일차 TIL (1) | 2023.11.23 |
| [6기] 프로그래머스 인공지능 데브코스 83일차 TIL (1) | 2023.11.22 |
| [6기] 프로그래머스 인공지능 데브코스 82일차 TIL (0) | 2023.11.21 |



